
Agentic AI - Should you be coding with agents?
Examining LLM utility in business - part 1 - software engineering

Number of baby/toddler interruptions in writing this text: 5
If you were in a coma for the past 2 years, and you woke up today, you might be wondering why everyone is talking about agents, agentic programming and utilising autonomous AI to automate business processes. The “agentic era” is upon us and it seems to be all the rage amongst…well, everyone. In this text, I will be making the case for agents in software development. This will not be a tutorial text (I’m not a software engineer, while I have done front-end work in the distant past and coded in data science in more recent past), but I do hope that it will get some sceptics using agents; and likewise, that it will make some reckless engineers think about how they manage their agentic footprint.
Last week, I wrote about what I think are ingredients you need to be able to plug an LLM into an autonomous process - which boil down to basically - strict process control, and a bulletproof quality control process. I argue today that software engineering is the industry that has been setup exactly to reap the benefits of agentic AI1 as it stands today.
As many before me have stated already - you have to assume that there’s been a paradigm shift. If you tried LLM’s to code in 2024 and you were disappointed or lukewarm, that might put you off Agentic AI, as there hasn’t been a paradigm shift in LLM ability, so why would it be better now? It’s the “autonomous” nature of it, the fact that it can autonomously look for answers and debug itself + the feedback loop that is ingrained in automatic quality control in a constrained action space - that makes it a paradigm shift, rather than LLM ability alone (although it does help!). In fact, you could very reasonably make the case that a lower ability LLM might be just as good if distilled on a particular coding framework (and in fact, it’s what likely will be behind most industry applications of agentic programming bots as the industry starts to look for cost savings).
But as always, nuance is important. The hypers will tell you everyone should be coding with agents. The sceptics will tell you that agents write mediocre code, that it’s riddled with errors and that you shouldn’t bother. The truth is - you have to give it some thought as to how you’d implement agentic, and your mileage will vary depending on your particular software development use case. A special note remains that if you’re junior, you should pay the price of learning2, and do it yourself.
UPDATE (Aug ‘25): I realised from some feedback that I gloss over a very important point - I evaluate these systems purely in terms of their utility, and ignore their economic cost. It’s worth noting that, yes, absolutely, the unit economics of the whole Gen AI industry are broken, and it’s a big bubble that will either collapse, or they’ll somehow find ways to reduce unit economic cost down to a level where these things can be profitable. Under the current consumer prices - what I write below makes sense, but reader, you should be very aware that the actual cost to AI companies is much higher than the price they pass onto you - and therefore a future exists in which your costs explode up but you reworked your workflows to become reliant on AI too much. The jury IS out on whether the economic gains you get from incorporating AI outweigh the economic cost when the cost actually does start getting passed down onto you.

How to even engage with the concept?
With any autonomous applications of AI - it is better to use AI as a tool (“do something I know how to do - but faster”), rather than as a crutch (“do something I can’t do”). This is because the agents are still not good enough to be left to their own devices, so we want to ensure a human in the loop is checking their work - and the check makes a lot more sense if the checker knows how it should be done.
Basically, you should treat the agent as a very keen junior dev who is lightning fast, writes mediocre code, and makes a lot of wild assumptions. And you should give them a lot of rope to do the work that you find trivial3 (work that is chunky enough to be worth the PR review as opposed to writing it yourself). If that metaphor works for you - just anthropomorphise it and run with it, you’ll get the most bang for your buck. The key difference being that once you’ve worked with a junior for a while, you might trust them with more and more as you learn their process and where they make mistakes. AI will not fit as neatly into a pattern, and will have a much greater diversity of the mistakes it can make, so you should maintain a level of distrust.
The critical thing with agents is that you should never let them merge anything autonomously. What you’re doing is switching work from coding to reviewing PR’s. I can see many of you shaking your heads, as that just doesn’t fit your workflow. And I agree, to an extent. There are workflows that are going to be more strongly and less strongly impacted by agentic programming - across different software engineering professions; and that’s before personality quirks get involved. I’ve known people who just can’t think through a problem unless they try coding it. They debug their thoughts through trying to write code, rather than creating a coding plan in their mind (or in a notebook) and executing. These kinds of developers (and I don’t, in any way, make an assumption that any type is inferior or superior) will really struggle - as you’ll be unable to prompt the bot to deliver satisfactory results, and PR’ing will likely be an outsized chore.
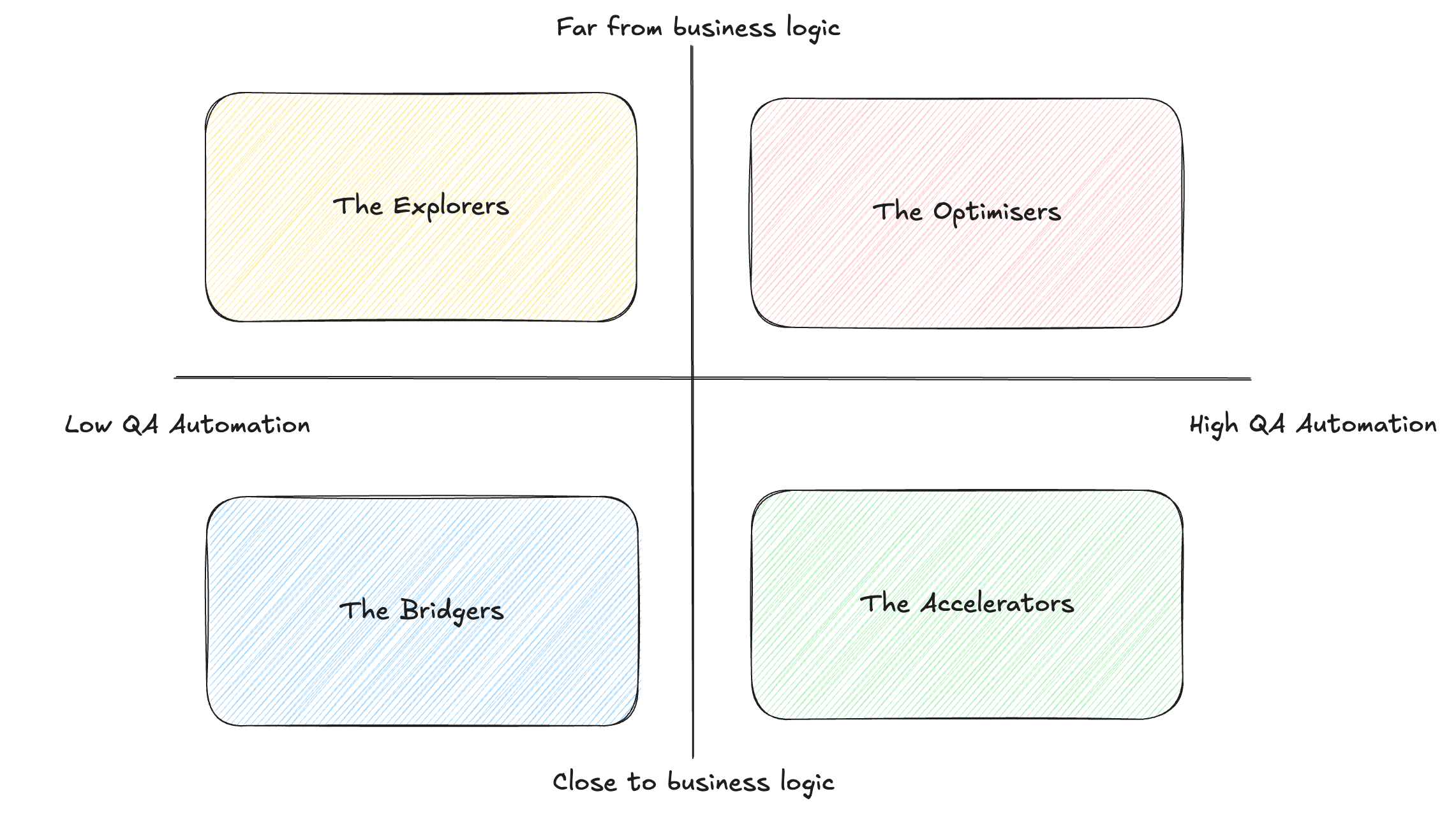
So how will you know whether to invest into investigating agentic? I propose a simple 2-dimensional framework. How close you are to the business problem, and what is the level of strictness in your software domain. By using this framework, you can divide most software disciplines into 4 quadrants, that I call Optimisers, Explorers, Accelerators and Bridgers.
I will make the case that each of those has a different upside they can get from agentic programming.
Proximity to business problem
While at the heart of all software development is the act of writing code, a way to execute formal logic in solving a tractable problem - it would be a big mistake to say that a systems engineer and a data analyst have a lot in common.
I think one of the main dimensions that will determine how much mileage you get from agents is how close to the business problem your particular discipline is. The closer you are to fuzzy business problems that need translation into business logic, the more the problem will be intractable for an agent, unless your organisation has extremely well organised documentation and informational ontology4.
This doesn’t mean you can’t use agents if you’re close to the business problem - but you’ll likely get more mileage out of the agents in the last mile, rather than end-to-end; as the solving of the business problem will still have to be done by your fleshy self; with the slog of writing the full solution, integrating into the codebase, testing etc. being left to the agents.
However, if you’re far from business logic? As in you’re just optimising an existing piece of engineering, or your working on a fundamental piece of software that serves other software engineers / techies? You can get close to doubling your productivity, maybe even further. 10x - 100x are fairy tales, but that shouldn’t stop you from sanely sitting down and evaluating this thing. This is because the instruction you’ll give the LLM is an optimisation of a closed system - something where the LLM can’t make a lot of assumptions and the constraint of the space it is in - will make it converge on a solution faster.
This is why a data analyst or a consultant working on a new business problem will struggle; there’s too many domain quirks that are needed to be able to converge on a solution. A DevOps engineer or a data engineer will fly though, as their workflows are highly automated already; and this will just give them the extra boost for the things that would’ve taken too long to automate so far.
Level of QA automation
It’s important to note here that I don’t necessarily mean QA in the strict software development sense - I mean QA in the abstract, as in what are the roadblocks the agent will hit that make it refine the code more. This includes compilers, linters, static analysis, formal verification; as well as unit tests and more traditional forms of testing. Basically, the more you can stack the deck to idiot-proof it; the better an agent will perform through self-correction (I’ll leave it to you, reader, to determine whether I’m calling AI agents idiots5).
There is a certain association between being high on this dimension and how close to the business problem you are, but not a full association. However, when you’re very close to business problems, it does get very hard to have QA automation, as the main source of quality / error will be alignment to business logic, which is, almost by definition, untestable in a standard pattern (unless your organisation is very mature and has a huge library of tests).
If your level of QA automation is non-existent, I would argue that agents are not worth it - and you might as well just query the LLM directly. This will cripple performance - but you’re likely in a role that is very creative, where you’re going to benefit from another point of view as much as another software professional will from automating the slog.
The Verdict

1. The Optimiser
Software disciplines: Data engineer, SRE, InfoSec, Systems Engineers, DevOps Engineers
Level of automation: Potential to automate the vast majority of routine workflows.
If you’re lucky to be working in a profession that has a high level of QA automation, and is within the technical weeds rather than close to the business / product logic - congratulations! You can likely automate a large part of your current coding workflows6, be a happier and more productive engineer as you automate away the slog that you hate doing, but that has to be done as part of your projects. High five your agentic swarm and hope prices don’t start rising for a while7. Focus on the meaty problems and engage your fleshy brain with the stuff that matters.
2. The Accelerator
Software disciplines: Backend (mature org)
Level of automation: Potential to automate a significant portion of the development cycle, especially boilerplate code.
You’re close to the business logic, but you’ve got a mature array of unit tests that can help corral an agent towards a solution without you being involved. Success in this quadrant will largely depend on how mature has the automated test suite been and how comfortable you are doing a lot of PR and code editing. You should remember that the code will still be mediocre and tend towards spaghetti code - so it’s better to be used with the long tail, than on critical systems components that are being newly developed that require a lot of cross-functional alignment.
3. The Explorer
Software disciplines: ML Scientist, Game Developer (early stage), Research Scientist
Level of automation: Automation is limited to specific, well-defined sub-tasks within a larger experimental flow.
You’re not that close to business logic - but the nature of the work is experimental which makes it just untestable. You’ll be able to automate away parts of the flow that are within a constrained space (i.e. - an ML scientist will be able to automate most hyperparameter tuning if they setup their problems well) - but the experimental nature of the role means that the majority of the work is on the problem solving rather than on the implementation / embedding. This will reduce the effectiveness of the alignment feedback loop for the agent. You might have some success with reasoning8 agents for problem areas that are relatively well explored and where reasoning will be able to find solutions, but for truly novel areas reasoning will likely collapse and you’ll have a limited array of tasks you’ll be able to automate. One good use case is to prototype pathways that would take you long to code up, that you’re not sure whether they’ll bring value. These would typically (in the old paradigm) be paths not explored as you go for more sure bets - and with agents, you can allow them to go wild - if you have confidence you’ll be able to ascertain fit of the hypothesis from the wilderness they bring to further your experimentation.
4. The Bridger
Software disciplines: Data Analyst, Consultant, Solution Architect
Level of automation: Automation provides minimal, targeted assistance, with most of the core work remaining manual.
You’re very close to business logic and the high rate of change of domain means you can’t really have good quality assurance on your code. The strictness of the environment you operate in will largely determine whether you’ll be able to get any upside from automation at all. If you’re an analyst doing exploratory analysis - the primary challenge isn't the code itself - tools like dbt can test SQL transformations effectively - but the fuzzy, evolving nature of the business question. The feedback loop isn't “does the code run?” but “does the result answer the nuanced, unstated question in the stakeholder's mind?” This human-centric validation is, by its nature, difficult to automate, limiting an agent's end-to-end utility. A startup dev might be able to squeeze some juice out of it - especially if they can live with spaghetti code and tech debt until the first big refactor hits - but there be dragons in that strategy.
All is not lost though, as this will likely be an area where people will be looking at how to create a layer of abstraction that allows for a better feedback loop. How do you add a logic integrity scenario as part of the prompt that the agent can test against; to allow for automation? How do you set constraints that limit the amount of tech debt and spaghetti code that the agent will deploy in a startup scenario. These are problems that the product developers in the agentic AI industry will be looking how to solve, to bring some of that productivity juice to the Bridger profile. If sanity prevails.
Conclusions
That’s it - hopefully this framework helps you think about whether you’re in the part of the software engineering industry that can see monumental shifts from this new technology - but even if you’re not - the formal nature of programming languages (compared to natural language) - and a rise in ontological systems as a commodity for business knowledge will mean that a lot of the benefits seen with the Optimisers today will be coming to other software professions soon9. Temper your excitement, and your venture capital10, appropriately until then.
I really don’t want to get bogged down in the bullshit of evaluating terminology and whether it’s proper to call these things agentic. The whole field is bloated with ill-fitted terminology, which is why 4 posts in the future I start talking about fantasy creatures to relax my brain from all the ill-fitted slog.
While I think juniors can get mileage from agentic implementation - until we have trialed, tested and made reliable the systems that safeguard learning with high utilisation of AI cognitive offloading - I would recommend you stick to the old world of learning through pain - and aggressively automate anything you’ve sufficiently onboarded as knowledge.
The Pareto rule applies here. AI are scaling machines, and each new generation of AI solutions splits a problem space into 80% that can be automated away, and 20% that’s too hard. Typically, workers in the knowledge economy will hate doing the 80% that they find trivial; and love the 20% that is challenging, so this is good fit with how AI can be applied
Spoiler, it doesn’t
I am
Your mileage will vary by how much project switching you do and how much abstract automation you’ve already written. If you’re an embedded devops engineer in a team, you’ve probably already automated most of everything, and having an LLM mess with that is likely going to do more harm than good. But if you’re just starting - you can get there faster, unless you already abstracted most of your automation frameworks to the point where you can implement them with different clients at the push of a button.
But absolutely be aware that costs will go up, and they might go up to the point where it is no longer economically viable for you to keep this AI-powered automation in your workflow!
It is worth noting that these systems don’t reason in the traditional human sense. Here I am referring to the industry term for what these models do when they go into a loop to get an optimal outcome. For avoidance of doubt: these models can’t reason, they have no intelligence. See footnote 1
Important to note - this is logically true - but I have no confidence in business leaders recognising this and actually improving organisational information ontology. It was an afterthought for 60 years unless it brings an immediate economic return, so my bet is it will remain that way.
How delusional is it to think a VC will read this? Answer: Very